Sampling with Gaussian distributions¶
This example demonstrates a Latin Hypercube Sampling of a 4 parameter 5 response model using the lhs function.
The example is similar to Sampling, but the parameters samples are drawn from a Gaussian distribution.
The models of the parameter study are run using the run function.
The generation of diagnostic plots is demonstrated using hist, panels, and corr.
%matplotlib inline
import sys,os
try:
import matk
except:
try:
sys.path.append(os.path.join('..','src'))
import matk
except ImportError as err:
print 'Unable to load MATK module: '+str(err)
import numpy
from scipy import arange, randn, exp
from multiprocessing import freeze_support
# Model function
def dbexpl(p):
t=arange(0,100,20.)
y = (p['par1']*exp(-p['par2']*t) + p['par3']*exp(-p['par4']*t))
#nm = ['o1','o2','o3','o4','o5']
#return dict(zip(nm,y))
return y
# Setup MATK model with parameters
p = matk.matk(model=dbexpl)
p.add_par('par1',dist='norm',mean=0.5,std=0.2)
p.add_par('par2',dist='norm',mean=0.1,std=0.02)
p.add_par('par3',dist='norm',mean=0.5,std=0.2)
p.add_par('par4',dist='norm',mean=0.1,std=0.02)
# Create LHS sample
s = p.lhs(siz=500, seed=1000)
# Look at sample parameter histograms, correlations, and panels
out = s.samples.hist(ncols=2,title='Parameter Histograms by Counts')

par1:
Count: 2 8 30 71 115 124 89 44 13 4
Bins: -0.17 -0.04 0.089 0.22 0.35 0.48 0.6 0.73 0.86 0.99 1.1
par2:
Count: 3 11 35 76 117 119 83 40 13 3
Bins: 0.036 0.049 0.061 0.074 0.087 0.099 0.11 0.12 0.14 0.15 0.16
par3:
Count: 4 14 40 80 112 113 80 39 14 4
Bins: -0.1 0.02 0.14 0.26 0.38 0.5 0.62 0.74 0.86 0.98 1.1
par4:
Count: 5 19 56 106 132 104 55 18 4 1
Bins: 0.04 0.053 0.067 0.08 0.094 0.11 0.12 0.13 0.15 0.16 0.17
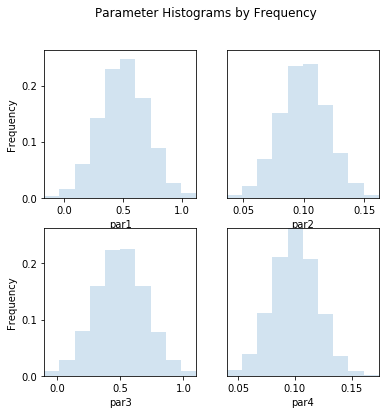
out = s.samples.hist(ncols=2,title='Parameter Histograms by Frequency',frequency=True,printout=False)
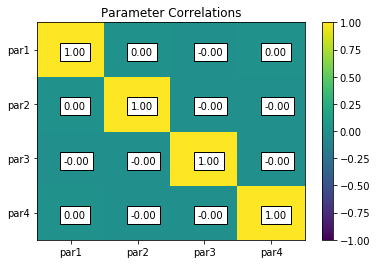
parcor = s.samples.corr(plot=True, title='Parameter Correlations')
par1 par2 par3 par4
par1 1.00 0.00 -0.00 0.00
par2 0.00 1.00 -0.00 -0.00
par3 -0.00 -0.00 1.00 -0.00
par4 0.00 -0.00 -0.00 1.00
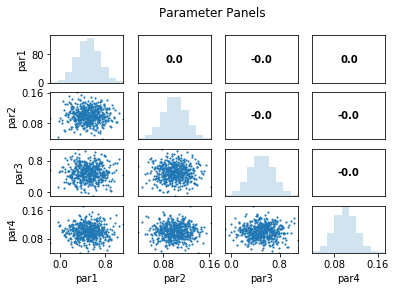
out = s.samples.panels(title='Parameter Panels')
# Run model with parameter samples
s.run( cpus=2, outfile='results.dat', logfile='log.dat',verbose=False)
# Look at response histograms, correlations, and panels
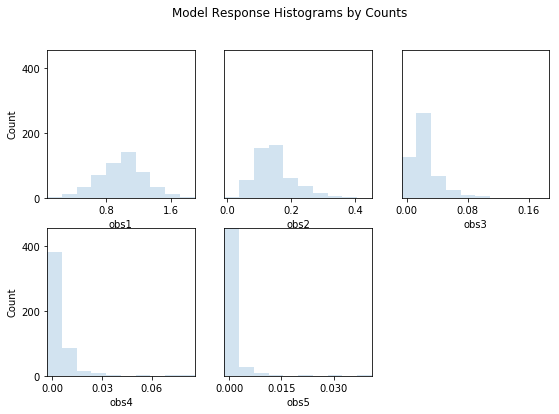
out = s.responses.hist(ncols=3,title='Model Response Histograms by Counts', printout=False)
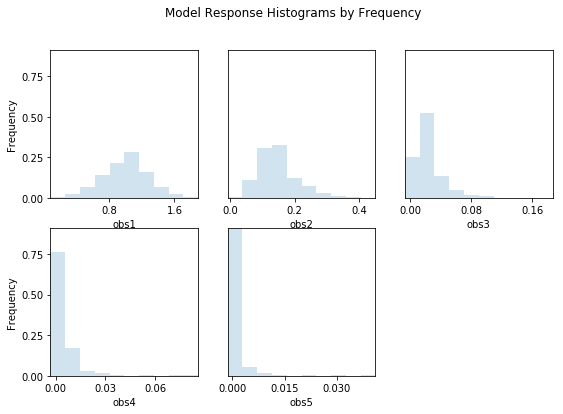
out = s.responses.hist(ncols=3,title='Model Response Histograms by Frequency',frequency=True,printout=False)
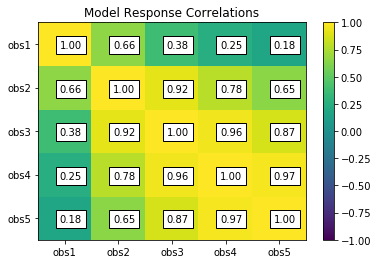
rescor = s.responses.corr(plot=True, title='Model Response Correlations')
obs1 obs2 obs3 obs4 obs5
obs1 1.00 0.66 0.38 0.25 0.18
obs2 0.66 1.00 0.92 0.78 0.65
obs3 0.38 0.92 1.00 0.96 0.87
obs4 0.25 0.78 0.96 1.00 0.97
obs5 0.18 0.65 0.87 0.97 1.00
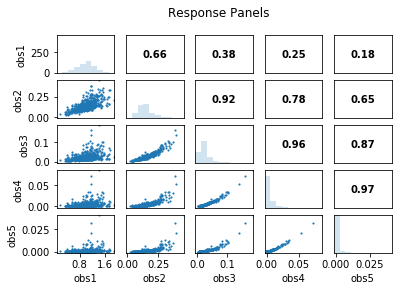
out = s.responses.panels(title='Response Panels')
# Print and plot parameter/response correlations
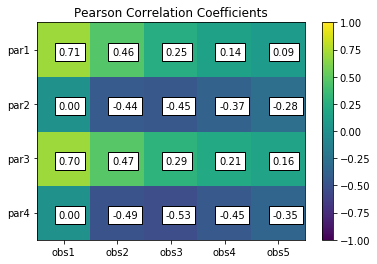
print "\nPearson Correlation Coefficients:"
pcorr = s.corr(plot=True,title='Pearson Correlation Coefficients')
Pearson Correlation Coefficients:
obs1 obs2 obs3 obs4 obs5
par1 0.71 0.46 0.25 0.14 0.09
par2 0.00 -0.44 -0.45 -0.37 -0.28
par3 0.70 0.47 0.29 0.21 0.16
par4 0.00 -0.49 -0.53 -0.45 -0.35
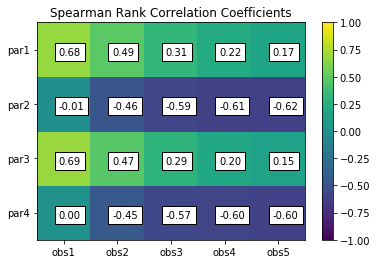
scorr = s.corr(plot=True,type='spearman',title='Spearman Rank Correlation Coefficients',printout=False)
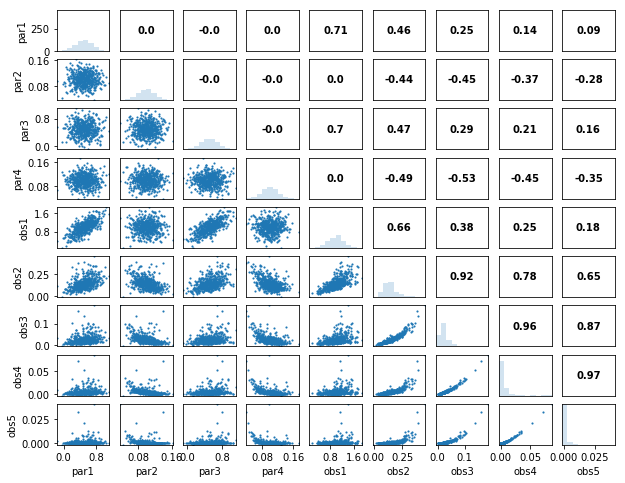
out = s.panels(figsize=(10,8))